| |
|
|
Cimplicity ODBC Driver
|
|
|
"...this is the most exciting addition to Cimplicity in years - Pure Power"

Overview
It takes a few moments for the power of a bidirectional ODBC driver to sink in. Everyone is used to the concept of logging data via Data Logger, but that is unidirectional. What do we do though if we want to access data in a database at runtime? Cimbasic scripts, right? But there's a real limitation on how much data you can pump through a scripted solution. Then there's the fact that it makes your project much more difficult to manage and more costly to develop. Our ODBC driver puts an end to all this and takes Cimplicity to a completely new level.
Do you really want the password for your db access to be visible in your Cimplicity script? Have you ever had to deal with timeouts on long running queries? Have you ever even considered creating a Cimplicity application that can hit your database continuously 5, 10, 20, 50 times each second? These are all barriers to what you can do with Cimplicity. These were barriers. Now you can have all the functionallity and much more.
Isn't that what Tracker is for? Yes, tracker was obviously developed to give you some of the functionallity of having a realtime db in your Cimplicity project. But with an ODBC driver your SQL (or any other ODBC) server is a real time component of your Cimplicity project and you get all that power without the limitations of what Tracker offers.
Here's how it works. You create points in your project and stored procedures on your SQL server. The SP can be as simple as a basic select statement or a very complicated process. If you want to pass inputs to that SP, you create one or more points in your Cimplicity project that become the input parameters to the SP. If your SP returns results which most do, you create points in your Cimplicity project to receive the output from the SP. You create one point for each filed (column) returned by your SP. If your SP returns multiple rows, just create your points as arrays big enough to handle all the rows of data. Once this is done, every time you set your input points, the SP automatically executes and all the data shows up in your target points.
Pure Speed
How fast are the results returned? Instantly. The target points populate the instant the SQL server returns the results. We did a test where we hit an SQl server with 10,000 queries returning 6 fields of 10 rows. The query had to cross hit 3 tables with about 25000, 250, and 250 records in each table to get the unique results. We executed the 10,000 unique queries over a 100Mb network in 27 seconds. The cimplicity project was running on a laptop and it populated the array points 10,000 times in that period. The bottleneck was the SQL server.
How can it be so fast? Well, Our driver is hard core. We use Prepared Statements that allow the queries to be run repeatedly on the database without having to resubmit the entire query field. By setting the execution plan and just passing input and output parameters your SQL server to Cimplicity interface is nothing less than real time. In the example above, there was no Cimplicity scripting required. We simply created the input point, the output points and then started pumping data into the input point. The rest of it is magic.
A New World of Opportunity
Do you want to look up results in your corporate database based on results coming in to your HMI? With Descartes' ODBC solution, your corporate database is wholely integrated into your HMI. Consider what you could do?
Configuring the System
The Cimplicity ODBC driver connects to any database server via ODBC. You will need to create an ODBC Data Source on your server. If you are unsure how to do this you should contact the person who maintains your database. The process is really very simple.
The driver is a true device communications enabler just like any other Cimplicity communications protocol. To use it in a project simply select "Cimplicity ODBC Engine" in the Project Properites Protocol Box.
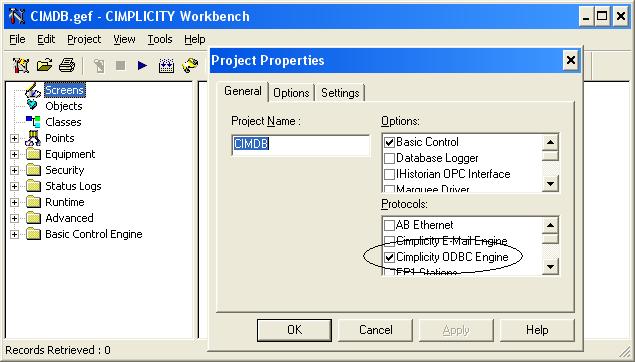
Creating ODBC Points and Devices
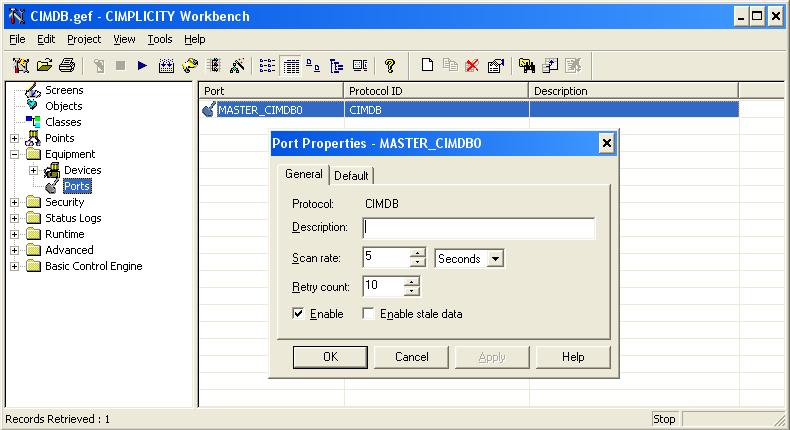
The Cimplicity ODBC driver requires the creation of a Port for each DSN you would like to connect through. If you want to connect to 2 separate SQL servers through 2 separate ODBC Data Sources you require 2 Ports. In most cases people only require one Port for one connection to one Data Source
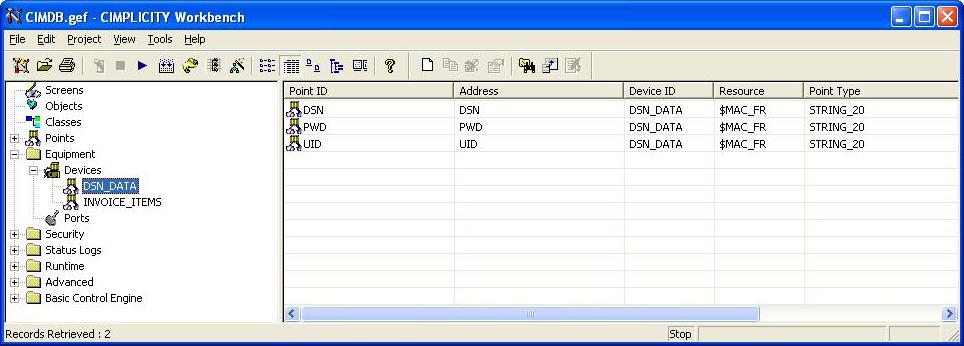
Each Port (data source) requires you to create a device to hold DSN info. The device can be called anything but in our sample project we call it DSN. The DSN device requires the creation of 3 string points with point addresses "DSN", "PWD", and "UID". At runtime you will populate the points with the Data Source Name, Password, and User ID for ODBC connection. And that's all there is to getting connected!
On your SQL database you can create stored procedures to do anything you want. It can be as simple as "Select Field1 from Table" to a complicated SP that contains hundreds of lines of SQL code and touches dozens of tables. To map your Cimplicity project to that SP, simply create a new device on your Cimplicity project and add a string point with the point address "SP". At runtime you set the name of the Stored Procedure in that point.
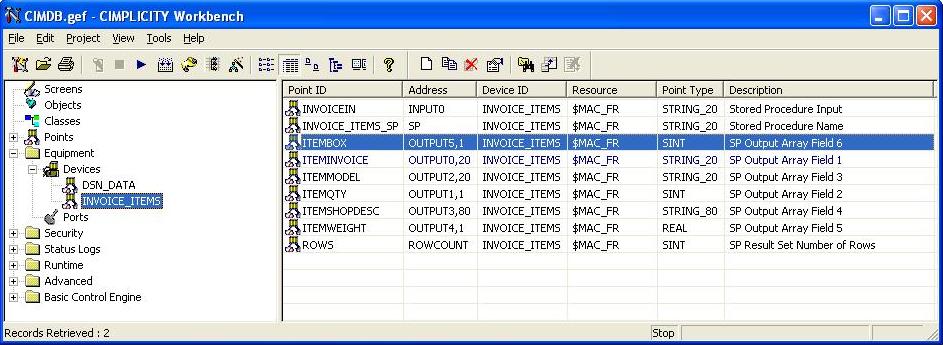
Most of the time you'll be running procedures that use input data. To make these connections, create points in your project with addresses "INPUTx" where x is an integer that corresponds to the field in the SP. For example a point with address INPUT1 will hold the value of the first parameter sent to a stored procedure. If your SP takes 2 arguments you will have a second point with address INPUT2 to hold the second argument at runtime. You can have up to 6 input fields.
Output from your SP is handled in a similar fashion. Points with addresses "OUTPUT1,1" and "OUTPUT2,1" and "OUTPUT3,1" will hold the first 3 fields of the result set after the SP is run. The second parameter in the point address (",1" in our examples) indicates how wide the field is. For real and int values it is always 1. For string and datetime results you should set this to the maximum width a row result may be for this field. You can have up to 10 output fields.
You can also create the optional point with address "ROWCOUNT". This is always the last point updated when a result set is populated so you know your data is stable when it is updated. It is also a handy point to know how many rows were returned from your last query.
Runtime Operation
At runtime you need to set the DSN, PWD, and UID points for each DSN you have created. You only need to do this once and the connection will persist as long as the project is running.
For each SP you want to access you need to set the SP point for the first time only.
Each time you want to run the SP, populate the INPUT points with the values you would like to send to the SP. You should set the point with address INPUT1 last since populating this point is what causes the SP to execute. As soon as INPUT1 is populated, the SP will run and the OUTPUT points and ROWCOUNT point will update as soon as data is returned - usually instantly. That's it! Keep updating the value of the input points and the output points will populate automatically.
Troubleshooting Tips
As much as we'd like to think otherwise, we are not perfect. If you find a bug in any of our software please let us know. We will fix it immediately - because we can - and provide you with an updated driver. The downloads available from our website are up-to-date. If we make a change to our software it gets rolled out immediately so everyone can benefit from the improvement.
Because no two servers ever seem to be set up the same, there have been some configuration side issues that our users have reported. In most cases installation and setup are flawless but if you are experiencing any issues consider the following:
After installation, the files CIMDB.PROTO and CIMDB.MODEL should be in the Cimplicity\HMI\bsm_data directory. If they are not there you will not be able to add a port.
After installation, the files CIMDB.dll and CIMDB.exe should be in the cimplicity\HMI\exe directory. If they are not you will not be able to add the protocol to your project.
During installation, cmail makes registry entries so you can add the protocol to a project. To make these entries the user must have suitable rights on the server. You basically need rights to install new software on a server in order to install the cmail driver for Cimplicity. You do not need special user rights to use the driver once it is installed. Once installed the driver works like the rest of Cimplicity.
In Demo mode, you can only process 10 queries before the demo ends. To try the driver some more you must restart your project (or the CIMDB process using Cimplicity Process Control Panel)
Each machine requires a unique registration. Once installed and registered on a server, the CIMDB driver can be used for an unlimited number of projects running on that box.
We encourage our users to contact us with feedback regarding any of our software. If you have any suggestions or feedback please feel free to contact us.
The file available for download was last updated on 4/30/2009.
Download your free fully functional demo version here.
-->
| |
|
|
| |
|